Topic modeling is a powerful technique in natural language processing and machine learning that aims to automatically identify topics present in a text corpus. It plays a crucial role in uncovering hidden thematic structures within large datasets, making it valuable in various domains such as information retrieval, content recommendation, and sentiment analysis. One popular algorithm for topic modeling is Latent Dirichlet Allocation (LDA), which assumes that documents are mixtures of topics and that topics are mixtures of words. In this article, we will explore the theory behind LDA and guide you through the practical implementation of topic modeling using this algorithm.
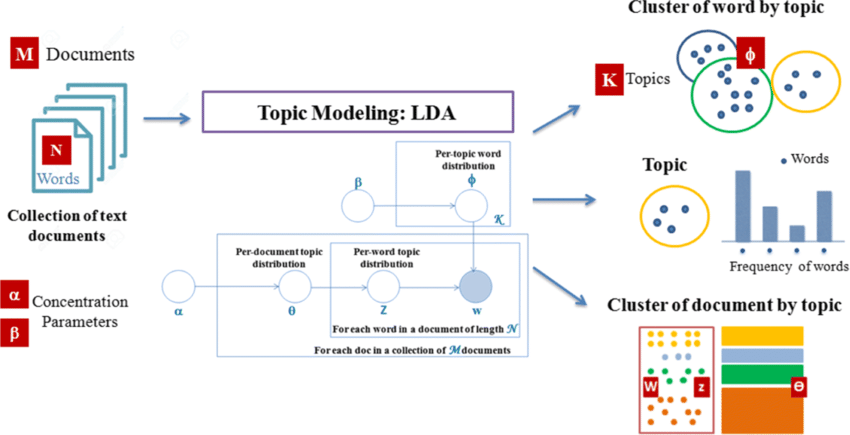
Latent Dirichlet Allocation is a powerful algorithm for topic modeling in Natural Language Processing (NLP), and its practical implementation using libraries like Gensim makes it accessible to researchers and practitioners in the field of natural language processing.
Understanding Latent Dirichlet Allocation (LDA)
Basic Concepts
Latent Dirichlet Allocation was introduced by David Blei, Andrew Ng, and Michael Jordan in 2003 as a generative probabilistic model for discovering topics in a collection of documents. The key idea is to represent documents as mixtures of topics and topics as mixtures of words. Here are the fundamental concepts:
- Documents: A corpus consists of a collection of documents, where each document is a sequence of words.
- Topics: LDA assumes that there are K latent topics in the entire corpus. A topic is a probability distribution over words.
- Words: Each document is considered as a mixture of topics, and each word in the document is attributable to one of the document’s topics. The choice of topics is hidden and is the “latent” part of LDA.
The Generative Process
LDA follows a generative process to create a document:
- Choose the number of words N in the document.
- Choose a distribution over topics for the document (document-topic distribution).
- For each word in the document:
- Choose a topic from the distribution over topics in step 2.
- Choose a word from the chosen topic’s distribution.
Probability Distributions
LDA uses probability distributions to model the generation of documents. These distributions include:
- Document-Topic Distribution (θ): For each document, there is a distribution over topics. θ is a K-dimensional vector, where K is the number of topics.
- Topic-Word Distribution (β): For each topic, there is a distribution over words. β is a V-dimensional vector, where V is the size of the vocabulary.
- Topic Assignment (z): For each word in each document, there is a topic assignment. z represents the topic assigned to a word.
- Word
 : The actual observed word in the document.
: The actual observed word in the document.
Objective of LDA
The objective of LDA is to infer the latent topic structure of a corpus given the observed documents. This involves estimating the values of θ and β that best explain the observed words in the corpus.
Practical Implementation of LDA
Now that we have a basic understanding of LDA, let’s dive into the practical implementation of topic modeling using this algorithm. We’ll use the Python programming language and the popular Natural Language Toolkit (NLTK) library along with the Gensim library, which provides an efficient implementation of LDA.
Step 1: Data Preprocessing
Before applying LDA, it’s crucial to preprocess the text data. This typically involves:
- Tokenization: Breaking text into words or phrases.
- Removing stop words: Common words that do not contribute much to the meaning.
- Lemmatization: Reducing words to their base or root form.
Step 2: Creating a Bag-of-Words Model
The next step is to represent the preprocessed documents as a bag-of-words model. In this model, each document is represented as a vector of word frequencies.
Step 3: Training the LDA Model
Now, it’s time to train the LDA model using the Gensim library.
Step 4: Analyzing the Results
Once the model is trained, we can analyze the obtained topics and their corresponding words.
Step 5: Assigning Topics to Documents
We can also assign topics to each document in the corpus.
Step 6: Visualizing the Results
Visualizing the topics and their distribution can provide a better understanding of the model.
Conclusion
By uncovering hidden thematic structures within text corpora, LDA enables the discovery of meaningful insights and facilitates tasks such as content recommendation, sentiment analysis, and information retrieval. Understanding the underlying concepts and steps involved in implementing LDA allows for effective utilization of this technique in various applications, contributing to the advancement of text analysis and information extraction.

Leave a comment